

什么是Qdrant?
Qdrant(读作:quadrant)是一个向量相似度搜索引擎。它提供了一个生产就绪的服务,带有一个方便的 API 来存储、搜索和管理点——带有额外有效负载的矢量。Qdrant 专为扩展过滤支持而定制。它使它可用于各种神经网络或基于语义的匹配、分面搜索和其他应用程序。
Qdrant 在开源 Apache License 2.0 下发布。它的源代码在 GitHub 上可用。
我们的总体计划是:
创建一个新的免费 Qdrant 云集群使用 pdfplumber 从 PDF 中提取文本并创建嵌入使用 Qdrant 为嵌入编制索引使用 Qdrant 根据用户输入搜索最相似的嵌入根据最相似的嵌入生成响应
所以,不要浪费更多时间 – 让我们开始吧!
创建一个新的免费 Qdrant 云集群
转到 qdrant.tech 并创建一个新帐户,然后创建一个新集群。您可以通过单击“代码示例”按钮获取 pyhton 代码以连接到您的集群。你可以找到你的api_key标签Access。
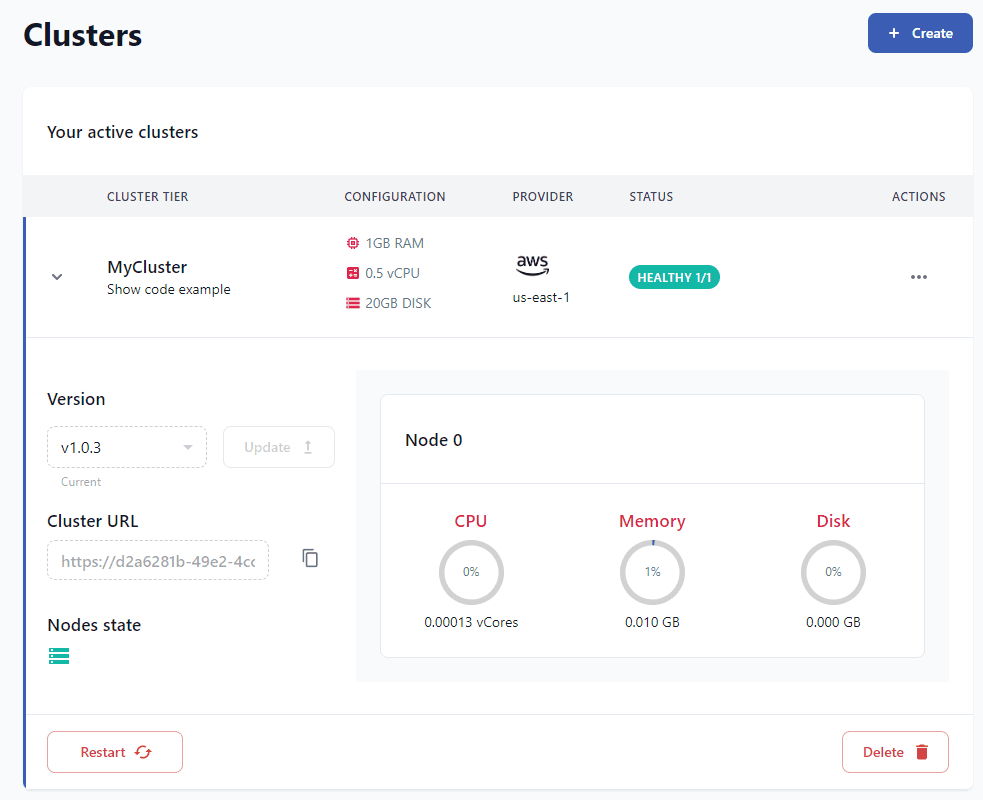
接下来我们可以连接到我们的集群并从我们的代码创建一个新的集合。将大小设置为嵌入的维度。对于 OPenAI 的 ada002 嵌入模型,大小为 1536。
from qdrant_client import QdrantClientqdrant_client = QdrantClient( host="<HOSTNAME>", api_key="<API_KEY>",)qdrant_client.recreate_collection( collection_name="mycollection", vectors_config=models.VectorParams(size=1536, distance=models.Distance.COSINE),)print("Create collection reponse:", qdrant_client)collection_info = qdrant_client.get_collection(collection_name="mycollection")print("Collection info:", collection_info)使用 pdfplumber 从 PDF 中提取文本并创建嵌入
我们将使用 pdfplumber 从 PDF 文件中提取文本。由于 PDF 文件的结构,这可能有点棘手,具体取决于 PDF。
在此示例中,我们将使用 SpaceX Starship 用户指南,但您可以使用所需的任何 PDF 文件。

import pdfplumberfulltext = ""with pdfplumber.open("starship.pdf") as pdf: # loop over all the pages for page in pdf.pages: fulltext += page.extract_text()print(fulltext)接下来我们将把文本分成最多 500 个字符的块,在下一步中我们将为每个块创建嵌入。这将帮助我们为我们的问答聊天机器人创造更好的环境。由于 OpenAI 的生成模型的输入大小是 4k 个标记,我们将把文本分成最多 500 个字符的块。这将确保我们可以将多个块作为我们提示的上下文
text = fulltextchunks = []while len(text) > 500: last_period_index = text[:500].rfind('.') if last_period_index == -1: last_period_index = 500 chunks.append(text[:last_period_index]) text = text[last_period_index+1:]chunks.append(text)for chunk in chunks: print(chunk) print("---")我们将使用 OpenAI 的 ada002 嵌入模型为每个块创建嵌入。
from qdrant_client.http.models import PointStructpoints = []i = 1for chunk in chunks: i += 1 print("Embeddings chunk:", chunk) response = openai.Embedding.create( input=chunk, model="text-embedding-ada-002" ) embeddings = response['data'][0]['embedding'] points.append(PointStruct(id=i, vector=embeddings, payload={"text": chunk}))使用 qdrant 索引嵌入
基本上,只需将我们列表中的所有点插入到我们的集合中。
operation_info = qdrant_client.upsert( collection_name="mycollection", wait=True, points=points)print("Operation info:", operation_info)使用 Qdrant 根据用户输入搜索最相似的嵌入
现在我们可以根据用户的输入搜索最相似的嵌入。我们将使用新的 OpenAI gpt-3.5-turbo 模型生成响应。
def create_answer_with_context(query): response = openai.Embedding.create( input="What is starship?", model="text-embedding-ada-002" ) embeddings = response['data'][0]['embedding'] search_result = qdrant_client.search( collection_name="mycollection", query_vector=embeddings, limit=5 ) prompt = "Context:\n" for result in search_result: prompt += result.payload['text'] + "\n---\n" prompt += "Question:" + query + "\n---\n" + "Answer:" print("----PROMPT START----") print(":", prompt) print("----PROMPT END----") completion = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role": "user", "content": prompt} ] ) return completion.choices[0].message.content根据最相似的嵌入生成响应
现在我们可以获取用户输入,查询相似的嵌入并使用最相似的嵌入的上下文生成响应。
input = "what is starship?"answer = create_answer_with_context(input)print(answer)# Starship is a fully reusable transportation system designed by SpaceX to service Earth orbit needs as well as missions to the Moon and Mars. It is a two-stage vehicle composed of the Super Heavy rocket (booster) and Starship (spacecraft) powered by sub-cooled methane and oxygen, with a substantial mass-to-orbit capability. Starship can transport satellites, payloads, crew, and cargo to a variety of orbits and landing sites. It is also designed to evolve rapidly to meet near term and future customer needs while maintaining the highest level of reliability.Qdrant 值得使用吗?
嗯,当然是!借助 Qdrant,我们可以根据需要向 GPT3 或 GPT 3.5 提示中添加尽可能多的知识。您还可以构建类似的图像/音频/视频搜索和推荐系统。Qdrant 为您提供了很棒的查询过滤器控件、集合、优化器等等!
关于本教程,您可以在 GitHub 上找到本教程的完整代码。当然,您可以使用代码示例将此类系统添加到您自己的应用程序中
我们始终鼓励您在我们的 AI 黑客马拉松期间测试您的技能。最好的方式来检查你在这里学到了什么,与来自世界各地的其他志同道合的人建立联系并实际构建一个工作原型,这可以成为你自己创业的里程碑!查看即将举行的活动!
谢谢你!如果您喜欢本教程,您可以在我们的教程页面上找到更多信息并继续阅读 – AI未来百科 ; 探索AI的边界与未来! 懂您的AI未来站